Toward Automatic Audio Description Generation for Accessible Videos
Yujia Wang1,2 Wei Liang1 Haikun Huang2 Yongqi Zhang2 Dingzeyu Li3 Lap-Fai Yu2
1Beijing Institute of Technology 2George Mason University 3Adobe Research
Abstract
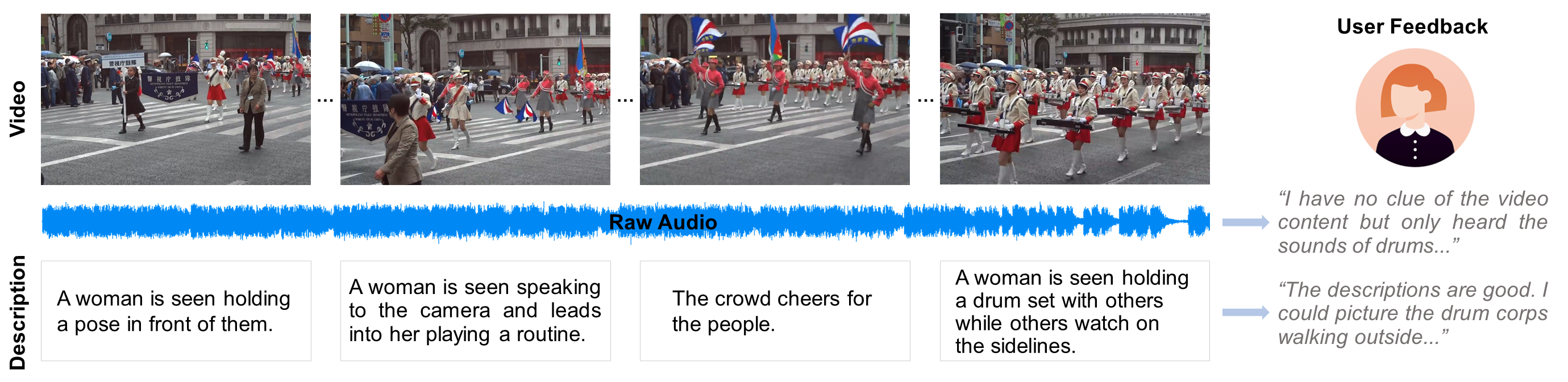
Video accessibility is essential for people with visual impairments. Audio descriptions describe what is happening on-screen, e.g., physical actions, facial expressions, and scene changes. Generating high-quality audio descriptions requires a lot of manual description generation. To address this accessibility obstacle, we built a system that analyzes the audiovisual contents of a video and generates the audio descriptions. The system consisted of three modules: AD insertion time prediction, AD generation, and AD optimization. We evaluated the quality of our system on five types of videos by conducting qualitative studies with 20 sighted users and 12 users who were blind or visually impaired. Our findings revealed how audio description preferences varied with user types and video types. Based on our study's analysis, we provided recommendations for the development of future audio description generation technologies.
Keywords
Audio Description, Video Description, Audio-Visual Consistency, Accessibility.
Publication
Toward Automatic Audio Description Generation for Accessible Videos
Yujia Wang,
Wei Liang,
Haikun Huang,
Yongqi Zhang,
Dingzeyu Li,
Lap-Fai Yu
ACM Conference on Human Factors in Computing Systems (CHI 2021)
Paper,
Supplementary,
Video,
Results (Video Virsion),
500 Results (Coming Soon)
BibTex
@article{comic2019wang,
title=
{Toward Automatic Audio Description Generation for Accessible Videos},
author = {Wang, Yujia and Wei, Liang and Haikun, Huang and Yongqi, Zhang and Dingzeyu, Li and Yu, Lap-Fai},
journal={ACM Conference on Human Factors in Computing Systems (CHI 2021)},
volume = {38},
number = {6},
year = {2020}
}

- 媒体计算与智能系统实验室
- Media Computing and Intelligent Systems Lab
Beijing Institute of Technology Copyright Address: 5 South Zhongguancun
Street, Haidian District, Beijing Postcode: 100081